ما هي فهرسة جوجل؟
هناك محركات بحث مختلفة بتنسيق مختلف من الفهرسة ، لكن محركات البحث الشائعة تشمل ، Google و Bing وللأفراد المهتمين بالخصوصية ، duckduckgo.
تشير فهرسة Google عمومًا إلى عملية إضافة صفحات ويب جديدة ، بما في ذلك المحتوى الرقمي مثل المستندات ومقاطع الفيديو والصور وتخزينها في قاعدة بياناتها. بمعنى آخر ، لكي يظهر محتوى موقعك في نتائج بحث Google ، يجب أولاً تخزينها في فهرس Google.

تستطيع Google فهرسة كل هذه الصفحات الرقمية والمحتوى باستخدام العناكب أو برامج الزحف أو الروبوتات التي تزحف بشكل متكرر إلى مواقع ويب مختلفة على الإنترنت. تتبع برامج التتبع وبرامج الزحف هذه إرشادات مالكي مواقع الويب حول ما يجب الزحف إليه وما يجب تجاهله أثناء الزحف.
لماذا يجب فهرسة المواقع؟
في عصر العصر الرقمي هذا ، يكاد يكون من المستحيل التنقل عبر مليارات المواقع للعثور على موضوع ومحتوى معين. سيكون الأمر أسهل بكثير إذا كانت هناك أداة توضح لنا المواقع الجديرة بالثقة ، والمحتوى المفيد والملائم لنا. هذا هو سبب وجود Google وتصنيف مواقع الويب في نتائج البحث الخاصة بها.
تصبح الفهرسة جزءًا لا غنى عنه في كيفية عمل محركات البحث بشكل عام وجوجل بشكل خاص. يساعد في تحديد الكلمات والتعبيرات التي تصف الصفحة بشكل أفضل ، ويساهم بشكل عام في ترتيب الصفحة والموقع. للظهور في الصفحة الأولى من Google ، يجب أولاً فهرسة موقع الويب الخاص بك ، بما في ذلك صفحات الويب والملفات الرقمية مثل مقاطع الفيديو والصور والمستندات.
الفهرسة هي خطوة أساسية لمواقع الويب للحصول على ترتيب جيد في محركات البحث بشكل عام وجوجل بشكل خاص. باستخدام الكلمات الرئيسية ، يمكن رؤية المواقع واكتشافها بشكل أفضل بعد فهرستها وتصنيفها بواسطة محركات البحث. هذا يفتح بعد ذلك الأبواب لمزيد من الزوار والمشتركين والعملاء المحتملين لموقعك على الويب وعملك.
أفضل مكان لإخفاء جثة هو الصفحة الثانية من Google.
في حين أن وجود الكثير من الصفحات المفهرسة لا يؤدي تلقائيًا إلى جعل مواقعك أعلى مرتبة ، إذا كان محتوى تلك الصفحات عالي الجودة أيضًا ، يمكنك الحصول على دفعة من حيث تحسين محركات البحث.
لماذا وكيف يتم منع محرك البحث من فهرسة المحتوى
بينما تعد الفهرسة أمرًا رائعًا لأصحاب المواقع والشركات ، إلا أن هناك صفحات قد لا ترغب في ظهورها في نتائج البحث. قد تخاطر بكشف الملفات والمحتويات الحساسة على الإنترنت أيضًا. بدون كلمات مرور أو مصادقة ، يكون المحتوى الخاص معرضًا لخطر التعرض والوصول غير المصرح به إذا تم منح الروبوتات حرية التحكم في مجلدات وملفات موقع الويب الخاص بك.
في أوائل العقد الأول من القرن الحادي والعشرين ، استخدم المتسللون بحث Google لعرض معلومات بطاقة الائتمان من مواقع الويب التي تحتوي على استعلامات بحث بسيطة. تم استخدام هذا الخلل الأمني من قبل العديد من المتسللين لسرقة معلومات البطاقة من مواقع التجارة الإلكترونية.
حدث عيب أمني آخر مؤخرًا في موقع box.com ، وهو نظام تخزين سحابي شائع. تم الكشف عن الثغرة الأمنية من قبل ماركوس نيس ، مدير استخبارات التهديد في Swisscom. وذكر أن المآثر البسيطة لمحركات البحث بما في ذلك Google و Bing يمكن أن تكشف الملفات والمعلومات السرية للعديد من الشركات والعملاء الأفراد.
تحدث مثل هذه الحالات عبر الإنترنت ويمكن أن تسبب خسارة في المبيعات والإيرادات لأصحاب الأعمال. بالنسبة لمواقع الويب الخاصة بالشركات والتجارة الإلكترونية والعضوية ، من الأهمية بمكان منع فهرسة البحث للمحتوى الحساس والملفات الخاصة أولاً ثم من المحتمل وضعها خلف نظام مصادقة مستخدم لائق.
دعنا نلقي نظرة على كيفية التحكم في المحتوى والملفات التي يمكن الزحف إليها وفهرستها بواسطة Google ومحركات البحث الأخرى.
1. استخدام ملف robots.txt للصور
ملف Robots.txt هو ملف موجود في جذر موقعك يزود Google و Bing ومحركات البحث الأخرى بإرشادات حول ما يجب الزحف إليه وما لا يتم الزحف إليه. بينما يتم استخدام ملف robots.txt عادةً للتحكم في حركة الزحف وبرامج زحف الويب (الجوال مقابل سطح المكتب) ، يمكن أيضًا استخدامه لمنع الصور من الظهور في نتائج بحث Google.
سيبدو ملف robots.txt لمواقع WordPress العادية بالشكل التالي:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
يبدأ ملف robots.txt القياسي بإرشادات لوكيل المستخدم ورمز النجمة. علامة النجمة هي تعليمات لجميع برامج الروبوت التي تصل إلى موقع الويب لاتباع جميع التعليمات الواردة أدناه.
ابقِ الروبوتات بعيدًا عن ملفات رقمية معينة باستخدام ملف robot.txt
يمكن أيضًا استخدام ملف robots.txt لإيقاف زحف محرك البحث للملفات الرقمية مثل ملفات PDF أو JPEG أو MP4. لمنع زحف البحث لملف PDF و JPEG ، يجب إضافة هذا إلى ملف robots.txt:
ملفات PDF
User-agent: *
Disallow: /pdfs/ # Block the /pdfs/directory.
Disallow: *.pdf$ # Block pdf files from all bots. Albeit non-standard, it works for major search engines.الصور
User-agent: Googlebot-Image
Disallow: /images/cats.jpg #Block cats.jpg image for Googlebot specifically.إذا كنت ترغب في حظر جميع صور GIF. من الفهرسة والظهور على بحث الصور في google مع السماح بتنسيقات الصور الأخرى مثل JPEG و PNG ، يجب عليك استخدام القواعد التالية:
User-agent: Googlebot-Image
Disallow: /*.gif$هام: المقتطفات أعلاه ستستبعد ببساطة المحتوى الخاص بك من الفهرسة من قبل مواقع الطرف الثالث مثل Google. لا يزال من الممكن الوصول إليها إذا كان شخص ما يعرف مكان البحث. لجعل الملفات خاصة حتى لا يتمكن أي شخص من الوصول إليها ، ستحتاج إلى استخدام طريقة أخرى ، مثل المكونات الإضافية لتقييد المحتوى .
يمكن استخدام Googlebot-Image لمنع الصور وملحق صورة معين من الظهور في بحث الصور من Google. في حالة رغبتك في استبعادهم من جميع عمليات بحث Google ، مثل بحث الويب والصور ، فمن المستحسن استخدام وكيل مستخدم Googlebot بدلاً من ذلك.
يتضمن وكلاء مستخدم Google الآخرون للعناصر المختلفة على موقع الويب Googlebot-Video لمقاطع الفيديو من التطبيق في قسم فيديو Google على الويب. وبالمثل ، فإن استخدام وكيل مستخدم Googlebot سيحظر عرض جميع مقاطع الفيديو في مقاطع فيديو google أو بحث الويب أو بحث الويب على الأجهزة المحمولة.

يرجى الأخذ في الاعتبار أن استخدام ملف Robots.txt ليس طريقة مناسبة لحظر الملفات والمحتوى الحساس أو السري بسبب القيود التالية:
- يمكن لملف Robots.txt توجيه تعليمات إلى برامج الزحف حسنة التصرف فقط ؛ يمكن لمحركات البحث والروبوتات الأخرى غير المتوافقة ببساطة تجاهل تعليماتها.
- لا يمنع ملف Robots.txt خادمك من إرسال هذه الصفحات والملفات إلى مستخدمين غير مصرح لهم عند الطلب.
- لا يزال بإمكان محركات البحث العثور على الصفحة والمحتوى الذي تحظره وفهرسته في حالة ارتباطهما من مواقع ومصادر أخرى.
- يمكن الوصول إلى ملف Robots.txt لأي شخص يمكنه بعد ذلك قراءة جميع الإرشادات المقدمة والوصول إلى تلك المحتويات والملفات مباشرةً
لحظر فهرسة البحث وحماية معلوماتك الخاصة بشكل أكثر فعالية ، يرجى استخدام الطرق التالية بدلاً من ذلك.
2. استخدام علامة وصفية بدون فهرس للصفحات
يعد استخدام العلامة الوصفية no-index طريقة مناسبة وأكثر فعالية لمنع فهرسة البحث للمحتوى الحساس على موقع الويب الخاص بك. على عكس ملف robots.txt ، يتم وضع علامة no-index meta tag في قسم <head> لصفحة ويب باستخدام علامة HTML بسيطة للغاية:
<html>
<head>
<title>...</title>
<meta name="robots" content="noindex">
</head>لن تظهر أي صفحة بها هذه التعليمات في رأس الصفحة في نتيجة بحث Google. يمكن أيضًا استخدام التوجيهات الأخرى مثل nofollow و notranslate لإخبار برامج زحف الويب بعدم الزحف إلى الروابط وتقديم ترجمة لتلك الصفحة على التوالي.
يمكنك توجيه برامج زحف متعددة باستخدام علامات وصفية متعددة في الصفحة كما يلي:
<html>
<head>
<title>...</title>
<meta name="googlebot" content="nofollow">
<meta name="googlebot-news" content="nosnippet">
</head>هناك طريقتان لإضافة هذا الرمز إلى موقع الويب الخاص بك. خيارك الأول هو إنشاء قالب فرعي لـ WordPress ، ثم في ملفك الخاص بـ jobs.php يمكنك الاستفادة من ربط الإجراء wp_head لـ WordPress لإدراج علامة noindex أو أي علامات وصفية أخرى. فيما يلي مثال على كيفية noindex لصفحة تسجيل الدخول الخاصة بك.
add_action( 'wp_head', function() {
if ( is_page( 'login' ) ) {
echo '<meta name="robots" content="noindex">';
}
} );خيارك الثاني هو استخدام المكون الإضافي لتحسين محركات البحث (SEO) للتحكم في رؤية الصفحة. على سبيل المثال ، باستخدام Yoast SEO ، يمكنك الانتقال إلى قسم الإعدادات المتقدمة على الصفحة واختيار ببساطة “لا” للخيارات للسماح لمحرك البحث بإظهار الصفحة:
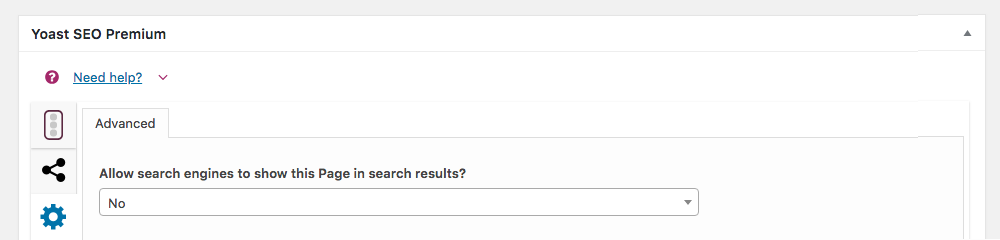
3. استخدام رأس X-Robots-Tag HTTP لملفات أخرى
تمنحك X-Robots-Tag مزيدًا من المرونة لمنع فهرسة البحث للمحتوى والملفات الخاصة بك. على وجه الخصوص ، عند مقارنتها بعلامة meta no-index ، يمكن استخدامها كاستجابة لرأس HTTP لأي عناوين URL معينة. على سبيل المثال ، يمكنك استخدام علامة X-Robots-Tag لملفات الصور والفيديو والمستندات حيث يتعذر استخدام العلامات الوصفية لبرامج الروبوت.
يمكنك قراءة دليل العلامات الوصفية الكامل لبرامج الروبوت من Google ، ولكن إليك كيفية إرشاد برامج الزحف إلى عدم متابعة صورة JPEG وفهرستها باستخدام X-Robots-Tag في استجابة HTTP الخاصة بها:
HTTP/1.1 200 OK
Content-type: image/jpeg
Date: Sat, 27 Nov 2018 01:02:09 GMT
(…)
X-Robots-Tag: noindex, nofollow
(…)أي توجيهات يمكن استخدامها مع العلامة الوصفية لبرامج الروبوت تنطبق أيضًا على X-Robots-Tag. وبالمثل ، يمكنك توجيه العديد من روبوتات محركات البحث أيضًا:
HTTP/1.1 200 OK
Date: Tue, 21 Sep 2018 21:09:19 GMT
(…)
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: bingbot: noindex
X-Robots-Tag: otherbot: noindex, nofollow
(…)من المهم ملاحظة أن روبوتات محركات البحث تكتشف العلامات الوصفية لبرامج الروبوت ورؤوس X-Robots-Tag HTTP أثناء عملية الزحف. لذلك ، إذا كنت تريد أن تتبع هذه الروبوتات تعليماتك بعدم متابعة أو فهرسة أي محتوى ومستندات سرية ، فيجب ألا تمنع هذه الصفحات وعناوين URL للملف من الزحف.
إذا تم منعهم من الزحف باستخدام ملف robots.txt ، فلن تتم قراءة إرشاداتك الخاصة بالفهرسة ، وبالتالي يتم تجاهلها. نتيجة لذلك ، في حالة ارتباط مواقع الويب الأخرى بالمحتوى والمستندات الخاصة بك ، فستظل تتم فهرستها بواسطة Google ومحركات البحث الأخرى.
4. استخدام قواعد .htaccess لخوادم Apache
يمكنك أيضًا إضافة رأس X-Robots-Tag HTTP إلى ملف htaccess الخاص بك لمنع برامج الزحف من فهرسة الصفحات والمحتويات الرقمية لموقع الويب الخاص بك المستضاف على خادم Apache. على عكس العلامات الوصفية بدون فهرس ، يمكن تطبيق قواعد .htaccess على موقع ويب بأكمله أو مجلد معين. يوفر دعمه للتعبيرات العادية مرونة أعلى لك لاستهداف أنواع ملفات متعددة في وقت واحد.
لمنع Googlebot و Bing و Baidu من الزحف إلى موقع ويب أو دليل خاص ، استخدم القواعد التالية:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (googlebot|bingbot|Baiduspider) [NC]
RewriteRule .* - [R=403,L]لحظر فهرسة البحث لجميع ملفات .txt و. jpg و. jpeg و. pdf عبر موقع الويب بالكامل ، أضف المقتطف التالي:
<Files ~ "\.(txt|jpg|jpeg|pdf)$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>5. استخدام مصادقة الصفحة مع اسم المستخدم وكلمة المرور
ستمنع الطرق المذكورة أعلاه المحتوى والمستندات الخاصة بك من الظهور في نتائج بحث Google. ومع ذلك ، يمكن لأي مستخدم لديه الرابط الوصول إلى المحتوى الخاص بك والوصول إلى ملفاتك مباشرة. للأمان ، يوصى بشدة بإعداد مصادقة مناسبة باستخدام اسم المستخدم وكلمة المرور بالإضافة إلى إذن الوصول إلى الدور.

على سبيل المثال ، الصفحات التي تتضمن ملفات تعريف شخصية للموظفين ووثائق حساسة يجب ألا يتم الوصول إليها من قبل مستخدمين مجهولين يجب دفعها خلف بوابة المصادقة. لذلك حتى عندما يتمكن المستخدمون بطريقة ما من العثور على الصفحات ، سيُطلب منهم بيانات اعتماد قبل أن يتمكنوا من التحقق من المحتوى.
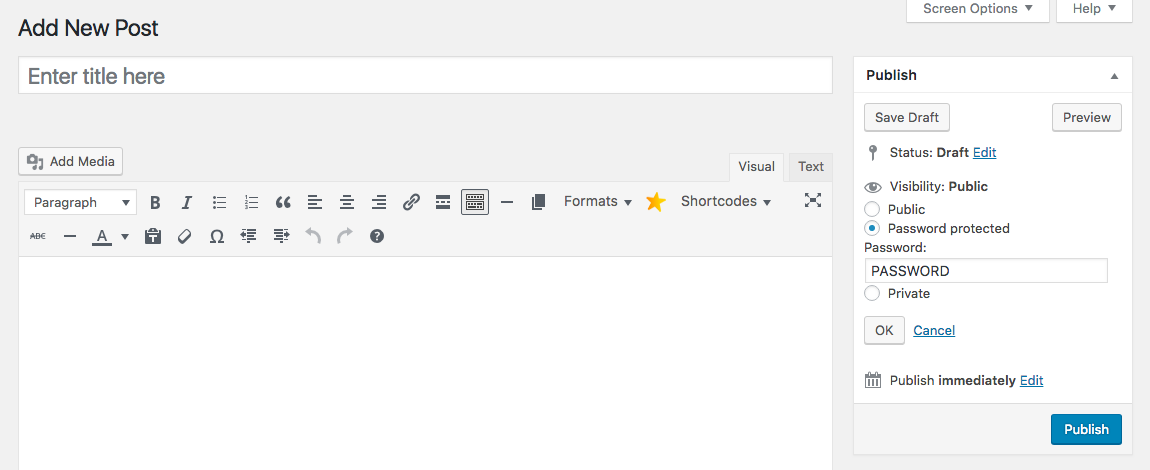
للقيام بذلك باستخدام WordPress ، قم ببساطة بتعيين رؤية المنشور على كلمة مرور محمية . بهذه الطريقة يمكنك تحديد كلمة المرور المطلوبة لعرض المحتوى على تلك الصفحة. من السهل جدًا القيام بذلك على أساس كل منشور / صفحة. لمزيد من الخصوصية الشاملة للموقع ، حاول إضافة أحد مكونات عضوية WordPress الإضافية إلى موقع الويب الخاص بك.